Precision and Recall, wtf are they?
Precision and Recall, wtf are they?
Read this and you will understand these concepts.
As you start to do more stats and machine learning you start to run into terms that seem to be used often but not very well explained. Two such concepts: precision and recall are two different ways to measure how good your algorithm is. An algorithm that has a high value for both is very good, an algorithm that is good at one or the other can be useful but it’s important to understand when to use it. I am going to explain precision and recall in this post. If you read through will understand these concepts and how they are applied. Before diving in let’s talk about what these terms mean.
Recall — Can I make a model that can find all the sick people?
Recall is how good your algorithm is at matching or finding all the data points with a particular feature. It is as a value measured 0–1.0. So if you are quarantining patients that have the flu an algorithm with a good recall would be able to quarantine most of the people who have the flu in the population. Perfect recall would quarantine every single sick person. Recall does not care how many healthy people your algorithm also mistakenly quarantined. It only asks: “How close did we come to quarantining every person who had the flu?”
Precision — Can I make model that can find only sick people?
Precision is how good your algorithm is at getting only the right stuff. It is as a value measured 0–1.0. So an algorithm with good precision would quarantine a group of people and most of the people it quarantined would have the flu. Precision does not care how many sick people we missed. It only asks: “Did everyone we quarantined have the flu?”
We’ll have a model that tries to identify which people have the flu. Once we have our model we will evaluate this model using precision and recall.
Our model will fall into 1 of 4 categories:
- low recall, low precision
- high recall, low precision
- low recall, high precision
- high recall, high precision
Category 1: low recall, low precision
If you have both a low precision and recall your algorithm is probably underfitting the data or the wrong algorithm for this task. You could represent your algorithm with the venn diagram below. Here the green circle (positives) is people who have the flu and the red circle is things our algorithm said have the flu (predictions). White space outside the green circle is people who do not have the flu (negatives).
Your algorithm isn’t good at finding the people who have the flu, small green-red overlap (bad recall), and among the stuff it chose, the red circle, it picked tons of people who didn’t have the flu (bad precision).
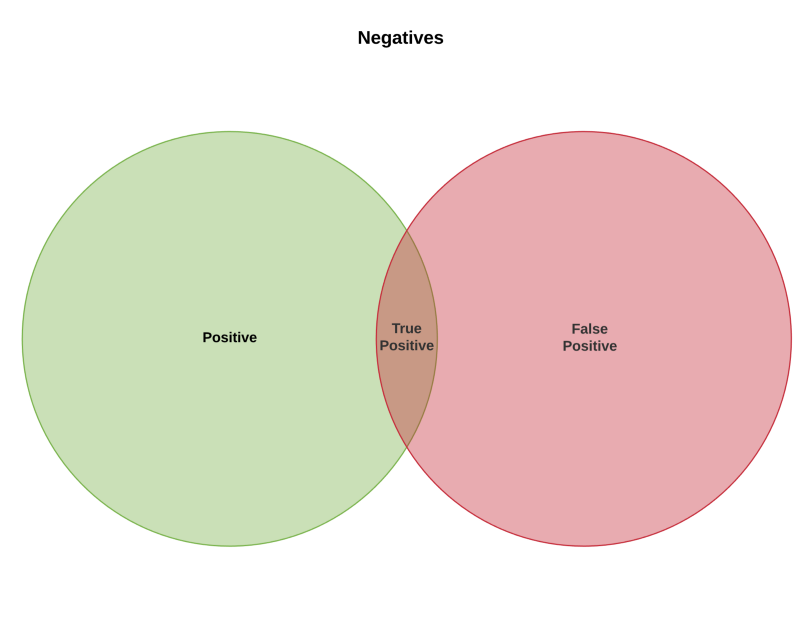
Category 2: high recall, low precision
This scenario your model is casting a wide net (hence the bigger red circle) and getting most of the things its looking for, big green-red overlap, (good recall) but it’s probably grabbing a lot of stuff it’s not supposed to, big red-white space overlap (bad precision).
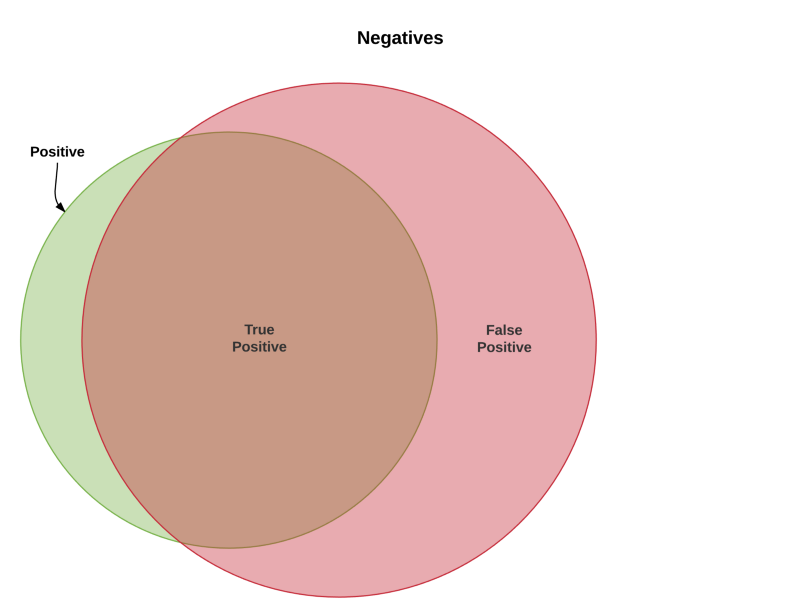
Category 3: low recall, high precision
Your model is casting a small net and missing most of the things it’s looking for but among the things it has selected most of them are correct. The green-red overalp is small (bad recall). The red-white overlap is also small (good precision).
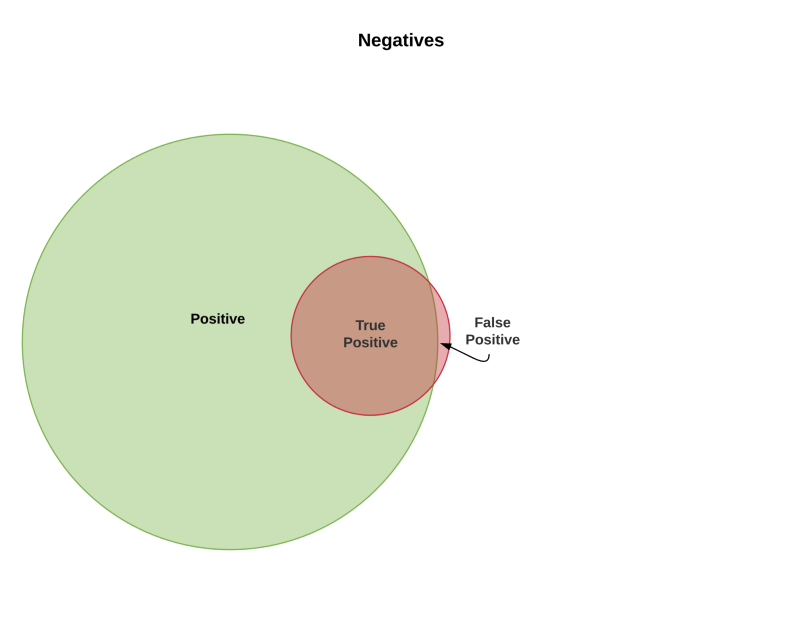
Category 4: high recall, high precision
You can see that the predicitons our algorithm made and the actual number of people who have the flu has a high overlap (high green-red overlap, high recall). We also have very few people that are not sick (rid-white space) that our algorithm said had the flu (high precision). This is the holy grail right here, an algorithm that can find all the sick people without also grabbing too many healthy people.
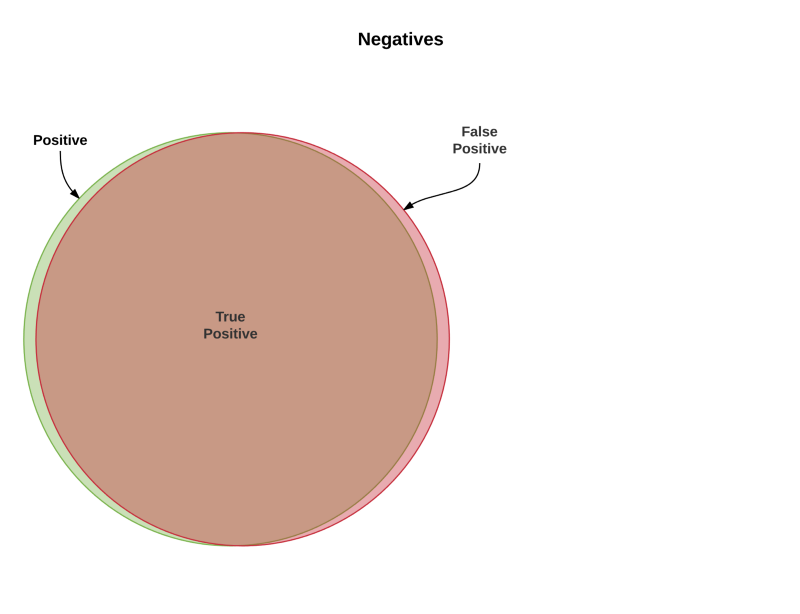
Math
You can see the math of precision and recall below, FP (false positive, predicted flu, but was healthy), TP (true positive, predicted flu, had the flu), positive (has the flu), FN (false negative, predicted healthy, had the flu). Recall punishes you for missing people who have the flu (increasing FN). Precision punishes you for for matching healthy people and saying they have the flu (increasing FP).
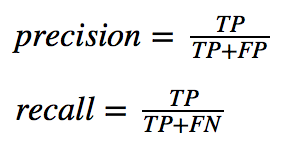
Example
The united states justice system tries to have a high precision and thus ends up having lower recall. The burden of proof is on the government; people are innocent until proven guilty. Because fo a lack of evidence many criminals will not be convicted (low recall) but at least the govrenment can be sure that the people it is imprisoning are indeed guilty (high precision).
Inspections for airplane Engines have a high (or perfect) recall and low precision. You want to make sure you get every single defective engine, it’s ok to grab many working engines as well but it is critical that every defective engine get caught, so an airplane engine does not fail midflight.
Important concepts
Precision and Recall are not opposites. It is possible to have both but it can be hard to produce a model that does this. In practice you can usually turn knobs on your model to make it more or less relaxed in its predictions, which will create a tradeoff between precision and recall.
You may also have noticed that the size of the prediction set your algorithm makes seems to affect precision and recall. By making fewer positive predictions you can get your precision higher By making more positive predictions you can get your recall higher. Either metric on its own can be abused. That is why it is important to report both these metrics, having both together gives you a picture of how good your algorithm is at 1 — finding the stuff (recall), 2 — being correct about the stuff it finds (precision).
You should now have a pretty solid conceptual grasp of what precision and recall are and you should be ready to apply them to your algorithms or models to evaluate their quality. If you enjoyed this blog post you can signup for my newsletter here; I send it out once a month.